 JaBricks c PostgreSQL Базовое приложение Пользователи Настройки форм Права доступа Ролевой механизм Загрузка модулей
JaBricks c PostgreSQL Базовое приложение Пользователи Настройки форм Права доступа Ролевой механизм Загрузка модулей410013796724260
Набор данных интерфейса SetРеализация интерфейса Set представляет собой неупорядоченную коллекцию, которая не может содержать дублирующие данные. 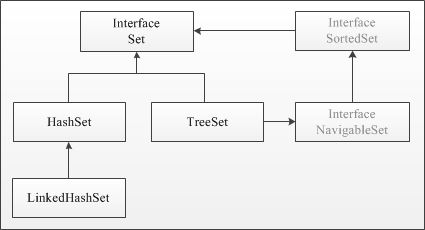
Интерфейс Set включает следующие методы :
К семейству интерфейса Set относятся HashSet, TreeSet и LinkedHashSet. В множествах Set разные реализации используют разный порядок хранения элементов. В HashSet порядок элементов оптимизирован для быстрого поиска. В контейнере TreeSet объекты хранятся отсортированными по возрастанию. LinkedHashSet хранит элементы в порядке добавления. Набор данных HashSetКонструкторы HashSet :// Создание пустого набора с начальной емкостью (16) и со // значением коэффициента загрузки (0.75) по умолчанию public HashSet(); // Создание множества из элементов коллекции public HashSet(Collection c); // Создание множества с указанной начальной емкостью и со // значением коэффициента загрузки по умолчанию (0.75) public HashSet(int initialCapacity); // Создание множества с указанными начальной емкостью и // коэффициентом загрузки public HashSet(int initialCapacity, float loadFactor); Методы HashSet
HashSet содержит методы аналогично ArrayList. Исключением является метод add(Object o), который добавляет объект только в том случае, если он отсутствует. Если объект добавлен, то метод add возвращает значение — true, в противном случае false. Пример использования HashSet :
HashSet<String> hashSet = new HashSet<String>();
hashSet.add("Картофель");
hashSet.add("Морковь" );
hashSet.add("Свекла" );
hashSet.add("Огурцы" );
// Следующая запись не должна попасть в набор
hashSet.add("Картофель");
// Вывести в консоль размер набора
System.out.println("Размер hashSet = " + hashSet.size());
// Вывести в консоль записи
Iterator<String> itr = hashSet.iterator();
while (itr.hasNext()) {
System.out.println(itr.next().toString());
}
В консоли мы должны увидеть только 4 записи. Следует отметить, что порядок добавления записей в набор будет непредсказуемым. HashSet использует хэширование для ускорения выборки. Пример использования HashSet с целочисленными значениями. В набор добавляем значения от 0 до 9 из 25 возможных случайным образом выбранных значений - дублирование не будет.
Random random = new Random(30);
Set<Integer> iset = new HashSet<Integer>();
for(int i = 0; i < 25; i++)
iset.add(random.nextInt(10));
// Вывести в консоль записи
Iterator<Integer> itr = iset.iterator();
while (itr.hasNext()) {
System.out.println(itr.next().toString());
}
Следует отметить, что реализация HashSet не синхронизируется. Если многократные потоки получают доступ к набору хеша одновременно, а один или несколько потоков должны изменять набор, то он должен быть синхронизирован внешне. Это лучше всего выполнить во время создания, чтобы предотвратить случайный несинхронизируемый доступ к набору :
Set<E> set = Collections.synchronizedSet(
new HashSet<E>());
Набор данных LinkedHashSetКласс LinkedHashSet наследует HashSet, не добавляя никаких новых методов, и поддерживает связный список элементов набора в том порядке, в котором они вставлялись. Это позволяет организовать упорядоченную итерацию вставки в набор. Конструкторы LinkedHashSet : // Создание пустого набора с начальной емкостью (16) и со значением коэффициента загрузки (0.75) по умолчанию public LinkedHashSet() // Создание множества из элементов коллекции public LinkedHashSet(Collection c) // Создание множества с указанной начальной емкостью и со значением коэффициента загрузки по умолчанию (0.75) public LinkedHashSet(int initialCapacity) // Создание множества с указанными начальной емкостью и коэффициентом загрузки public LinkedHashSet(int initialCapacity, float loadFactor) Также, как и HashSet, LinkedHashSet не синхронизируется. Поэтому при использовании данной реализации в приложении с множеством потоков, часть из которых может вносить изменения в набор, следует на этапе создания выполнить синхронизацию :
Set<E> set = Collections.synchronizedSet(
new LinkedHashSet<E>());
Набор данных TreeSetКласс TreeSet создаёт коллекцию, которая для хранения элементов использует дерево. Объекты хранятся в отсортированном порядке по возрастанию. Конструкторы TreeSet :// Создание пустого древовидного набора, с сортировкой согласно естественному // упорядочиванию его элементов TreeSet() // Создание древовидного набора, содержащего элементы в указанном наборе, // с сортировкой согласно естественному упорядочиванию его элементов. TreeSet(Collection<? extends E> c) // Создание пустого древовидного набора, с сортировкой согласно comparator TreeSet(Comparator<? super E> comparator) // Создание древовидного набора, содержащего те же самые элементы и использующего // то же самое упорядочивание в качестве указанного сортированного набора TreeSet(SortedSet<E> s) Методы TreeSet
В следующем измененном примере с использования TreeSet в консоль будут выведены значения в упорядоченном виде.
SortedSet<String> treeSet = new TreeSet<String>();
treeSet.add("Свекла" );
treeSet.add("Огурцы" );
treeSet.add("Помидоры" );
treeSet.add("Картофель");
treeSet.add("Морковь" );
// Данная запись не должна попасть в набор
treeSet.add("Картофель");
// Вывести в консоль размер набора
System.out.println("Размер treeSet = " + treeSet.size());
// Вывести в консоль записи
Iterator<String> itr = treeSet.iterator();
while (itr.hasNext()) {
System.out.println(itr.next().toString());
}
Random random = new Random(30);
SortedSet<Integer> iset = new TreeSet<Integer>();
for(int i = 0; i < 25; i++)
iset.add(random.nextInt(10));
// Вывести в консоль записи
Iterator<Integer> itr = iset.iterator();
while (itr.hasNext()) {
System.out.println(itr.next().toString());
}
|